ARIMA modeling
ARIMA modeling When tasked with predicting the movement of a time series on of the available functions is the ARIMA model and it only makes sense to start at the beginning so let’s dive into the first to letters. Autoregressive or AR is a combination of weights in a linear equation that flesh out the movement of the time series. The variables of the autoregression are periods of the number of increments that the time series is divided into, differencing which is the process of altering the time series until there is a mean and equal variance throughout. Differencing is determining a root equation, if such an equation is found the time series is said to be stationary. The last variable in autoregression is the error associated with lag and autocorrelation. If there is a positive autocorrelation at the first lag the ARIMA model uses autoregression but if there is a negative autocorrelation at lag one the time series is based upon the moving average or MA. When a negative autocorrelation exists there are continuous irregularities for multiple consecutive periods. The Intergrated component is the difference between the predicted errors of the weighted lags and the actual sum of the weighted lag values…why a hyphen wasn’t used because it really fits well like the Auto-Regressive - Moving Average is beyond my comprehension.
Plotly Interactive Graphing Library
In an effort to impress and manipulate others into giving you money may I offer plotly, the reactive graphing library that takes matplotlib and seaborn to the next level. Like most other libraries in python plotly provides a tool kit does all the heavy lifting of the backend processing and leaves the users to the declarative programming and being creative. This library has the basic graphs such as scatter, histogram, bar plot, etc but the viewer is then able to narrow or broaden the graphs by altering the axises. With plotly a model of the data to be displayed must be created called a data object that is then passed into a layout. However altering the scope of the graph is just the beginning as different plots can be added or subtracted via a dropdown menu. And as much as I’ve tried to transition from my career as a used car salesmen…(slaps the roof of plotly)….plotly has so much more to offer! For instance multiple graphs can be synced together to so as to form a video as values change over time. The option to project graphs onto images is easily accessible. Can you adjust the span of a time series with a slide bar in Seaborn because you certainly can in Plotly. Did you ever want to annotate the figures you created with monthly highs or lows because with a couple lines of code you can do that too. Perhaps the greatest aspect of it all is interactive figures can then be exported png, jpeg, webp, svg, and pdfs. Lastly and BY FAR most importantly don’t simply use plotly, unless you’re a real psycho because plotly express and cufflinks give you the entire library in a fraction of the number of lines of code.
Financial Stress Testing
One of the most strenuous tasks that financial institutions have to take up after the Dodd-Frank Wall St. Reform and Consumer Protection Act is to prove solvency in times of economic fluctuation. This procedure is called stress testing and can be thought of a measure of financial health. The stress test is made up of five key areas with the acronym CAMELS which include, Capital Adequacy, Asset Quality, Management Capability, Liquidity, and Sensitivity. The following project focuses on the first aspect capital adequacy which is the ratio of equity to risk weighted assets and Management Capability or the ability to properly respond to economic stress. The first and perhaps most difficult task was to create a time series that had random motion which could be varied. The baseline time series was constructed using a series of for loops and random normal distribution as well as interest rate input. The data set of assets and liabilities was artificially instantiated following Asset Liability Management (ALM) practices as well as current interest rates for such financial products. ALM procedures divide the total capital of company by percentage into an array of options with differing rates of return and stability. After creating a time series portfolio of asset and liability additional data frames which depicted the resulting affect from applied stress. The Equity Risk data frame depicted the decrease amounts capital being gained in the asset portfolio with an inverse relationship to the liability portfolio. Another data set created focused on the spread of assets and liabilities created by the stress to forecast total amount of loss. To further simulate reality a recursive function was implemented to continuously update the asset, liability portfolios on a daily basis with the summation of assets and liabilities which were then re-distributed according to ALM guidelines. After a complete dataset was generated to model the random walks of time series of financial gains and losses it was time to visualize the data. To simply show the series over time would show general trend and variability however there was much more that could be done starting with rolling average to a weekly mean resampling. Using statistical modeling algorithms that enable forecasting of future outcomes based upon past results found produced mixed results. However because the data was artificially generated no real insight was gained from this however the test did prove that the data did not fit ARIMA modeling nor did it have much autocorrelation. The plotly library has the capability of not only making figures interactive but also altering the axises of the graphs in real time. The time series of any increment can then be exported to run auto-regressive integrated moving average (ARIMA) modeling to forecast future performance. The plotly library also allows for permutation of all times series or the combination of chosen time series from different datasets through drop down menus. The plotly library has much more that was not utilized due to the data set not being as large as a continuous time series generate by the stock market with hundreds or thousands of transactions in a given day. In conclusion the notebook demonstrates the potential capability of python programming through a variety of analysis mechanism. This project was designed as a showcasing of the potential the visualization and computational ability available in some of the python libraries however this was only a cursory exploration.
LSTM neural network
Long Short Term Memory neural networks or LSTMs are a subset of recurring neural networks with the added specialty of being able to forget about the past so to speak. As the layers of the neural network are transversed the input from layers of the distant past have less of affect on the input into the current neurons compared to more recent layers.Another way to think of functionality of a LSTM is to picture the normal input gate and output gate plus a forget gate in each node of the network. There are several ways for LSTMs to train their data through loss functions which include categorical cross-entropy, binary cross-entropy and mean square error.If the loss function could be thought of as the experiment being done, the optimizer are considered the equipment being utilized. The most popular optimizer is Adam which is hybrid of the Adapative Gradient Algorithm and Root Mean Square Propagation. When building an LSTM model there are three major components that will affect the duration of computation including, the number of hidden layers, the batch size and how many epochs are listed. Using the Keras library allows for multiple iterations through LSTM neural networks in series.The batch size is the number of inputs going into the model which need to be transposed into an array containing the rows, time-series, and columns. The epochs will determine how many times your data will be trained and tested. When a loss function reaches its a local minium the rate of learning is beginning to slow down as well however if the number of epochs is continued there can be overfitting of the training data. If training data is repeatedly iterated the accuracy of training data will increase yet when given that testing sets being a quarter of the size of training sets will score much lower accuracies due to their smaller size. Similar to other aspects of LSTMs there are options when considering how to output final values using sigmoidal or softmax and hyperbolic tangential functions.
Simulation using a Recursive function
My instructor said it best when he stated ‘recursive functions make my head hurt.’ No more definite truth has ever been spoken however despite the fact they’re a tedious puzzle they also incredibly useful . Now that I’ve dressed recrusive functions up as wretched problem perhaps I should be slightly more objective with an exact definition according to Wikipedia:
Recursion in computer science is a method of solving a problem where the solution depends on solutions to smaller instances of the same problem (as opposed to iteration).[1] The approach can be applied to many types of problems, and recursion is one of the central ideas of computer science.
So you’re probably thinking Jeff was on the money right now with his assertion and honestly he’s never steered me wrong. All is not lost though, I’m writing a blog about recursive functions and i can barely understand that definintion. I had an example that seemed pretty simple from the fine folks at learn.co:
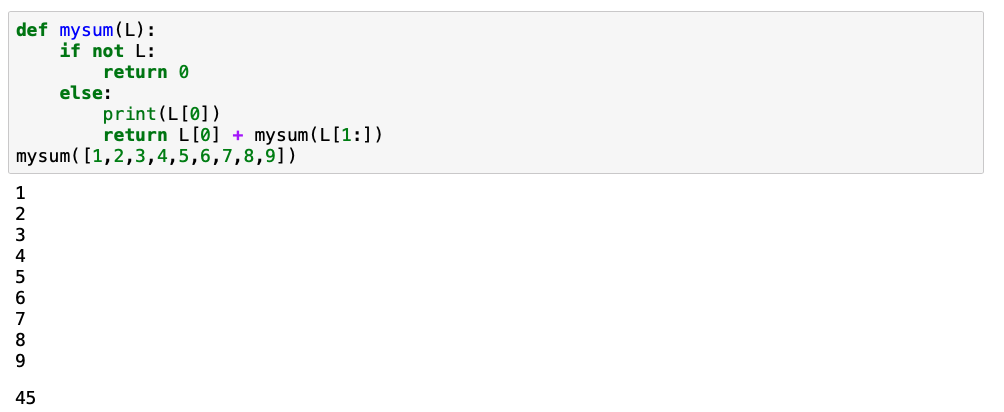
 Well if you’re anything like me, you still don’t know what’s going on so you start trying to work back from the solution 45 and the input is an array 1,2,3,4,5,6,7,8,9 and the name definition is ‘ mysum(L) ‘ Maybe try summing the numbers together? I actually did this without realizing the name of the definion…its been a hard life. So summation of the array that was labeled L in the definition is 45. I probably shouldn’t admit this but I feel like were practically besties now that we gotten this far together but i was still lost at this point because i was somewhat overlooking array. notation and also recursive functions just kinda make your head hurt. Best to skip the mental gymnastics for a moment and see what we can pull from a print of L[0]:
Well if you’re anything like me, you still don’t know what’s going on so you start trying to work back from the solution 45 and the input is an array 1,2,3,4,5,6,7,8,9 and the name definition is ‘ mysum(L) ‘ Maybe try summing the numbers together? I actually did this without realizing the name of the definion…its been a hard life. So summation of the array that was labeled L in the definition is 45. I probably shouldn’t admit this but I feel like were practically besties now that we gotten this far together but i was still lost at this point because i was somewhat overlooking array. notation and also recursive functions just kinda make your head hurt. Best to skip the mental gymnastics for a moment and see what we can pull from a print of L[0]:
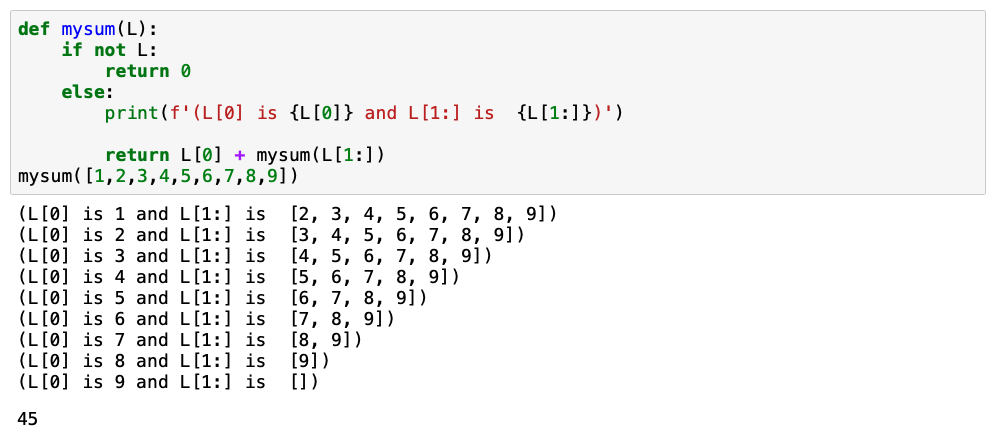
 That makes sense and then the function is being recalled again with a space shorter array (given to you by mysum(L[1:] ) Double checking with an altered print statment including L[1:]
That makes sense and then the function is being recalled again with a space shorter array (given to you by mysum(L[1:] ) Double checking with an altered print statment including L[1:]
 Again this kinda makes sense the second last iteration L[1:] is [9] and the last iteration is [ ] so L[1:] is 0 and when this is passed into the argument of mysum( ) the if instead of the else is used which returns a 0 and there are no more recursions…but they’re not iterations according to wikipedia who is way smarter than me. Yet this still doesn’t seem to make a lot of sense, yes if you sum the array it comes out to 45 but how is the function actually accomplishing this?? Well seeing how the only real option we have to explore here is L[0] lets make a list using the append function.
Again this kinda makes sense the second last iteration L[1:] is [9] and the last iteration is [ ] so L[1:] is 0 and when this is passed into the argument of mysum( ) the if instead of the else is used which returns a 0 and there are no more recursions…but they’re not iterations according to wikipedia who is way smarter than me. Yet this still doesn’t seem to make a lot of sense, yes if you sum the array it comes out to 45 but how is the function actually accomplishing this?? Well seeing how the only real option we have to explore here is L[0] lets make a list using the append function.
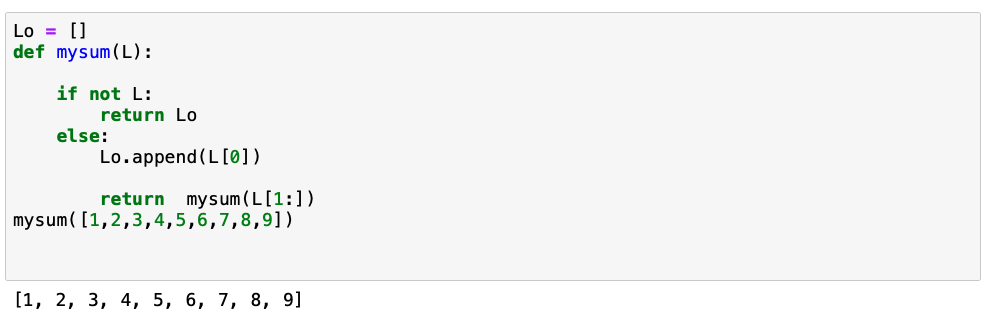 The return value is L[0] + mysum( L[1:] ) which is really return L[0]+L[0]+ L[0]+L[0]+ L[0]+L[0]+ L[0]+L[0]+L[0] + 0 (for the if clause) . Looking at our list of appended values of L[0] were back to 45!
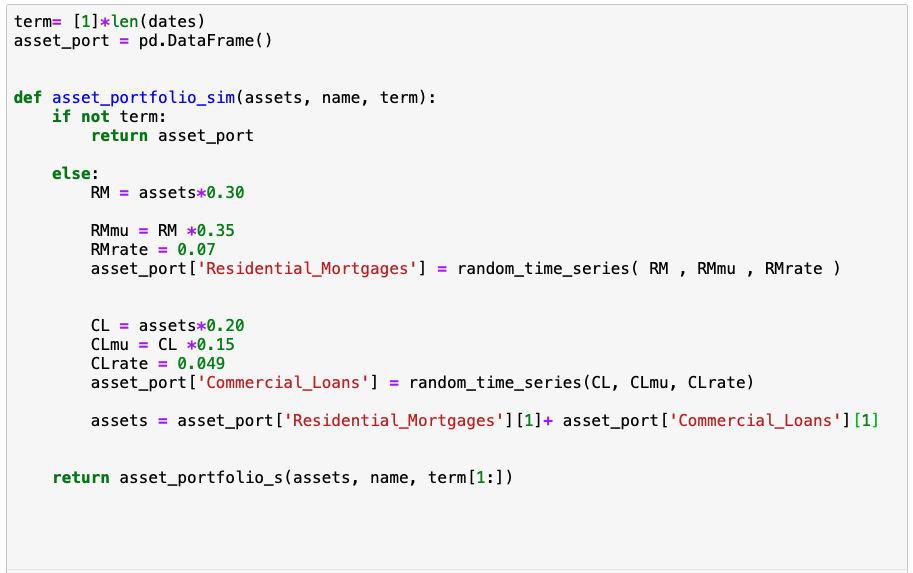
We can move on to bigger things, like what i really want to use a recurse function to do, update my asset and libility portfolio every day on its own. Seeing on how i can get a little wordy to say the least what i’m trying to do is first rebalance my asset portfolio according to ALM guidelines based upon the profits i took in during the day. With my new profits plus my past assets I can then determine how much liability I can safely accomidate.
The return value is L[0] + mysum( L[1:] ) which is really return L[0]+L[0]+ L[0]+L[0]+ L[0]+L[0]+ L[0]+L[0]+L[0] + 0 (for the if clause) . Looking at our list of appended values of L[0] were back to 45!
We can move on to bigger things, like what i really want to use a recurse function to do, update my asset and libility portfolio every day on its own. Seeing on how i can get a little wordy to say the least what i’m trying to do is first rebalance my asset portfolio according to ALM guidelines based upon the profits i took in during the day. With my new profits plus my past assets I can then determine how much liability I can safely accomidate.